6.8 B-Tree
6.8 B-Tree
Introduction
A B-tree is a specialized multiway tree designed for efficient disk usage. Unlike traditional search trees such as binary search trees, AVL Trees, or Red-Black trees, a B-tree allows each node to contain multiple keys and more than two children. Originating in 1972 by Bayer and McCreight as the Height Balanced m-way Search Tree, it was later standardized as the B-Tree.
Why B-tree?
The B-tree data structure offers several advantages that make it a preferred choice in various applications. Here are some reasons why B-trees are widely used:
- Efficient Disk Access: B-trees are specifically designed to optimize disk access. By ensuring that each node contains a significant number of keys, B-trees minimize the number of disk I/O operations required to access or modify data. This is particularly beneficial in scenarios where data is stored on disk, such as in database systems and file systems.
- Balanced Height: B-trees maintain a balanced height, meaning that all leaf nodes are at the same level. This balanced structure ensures predictable and efficient search, insertion, and deletion operations, regardless of the size of the dataset. As a result, B-trees provide consistent performance characteristics even as the dataset grows.
- Support for Large Datasets: B-trees can efficiently handle large volumes of data. Their ability to branch out in multiple directions and contain many keys in each node allows them to scale effectively to accommodate growing datasets without sacrificing performance.
- Versatility: B-trees are versatile data structures that can be adapted to various applications and scenarios. They are used in databases, file systems, operating systems, networking protocols, and more, demonstrating their flexibility and effectiveness across different domains.
- Range Queries Support: B-trees efficiently support range queries, where you want to retrieve all keys within a specified range. The sorted nature of keys within each node facilitates quick traversal, making range queries performant and scalable.
- Self-Balancing: B-trees are self-balancing data structures, meaning that they automatically adjust their structure during insertion and deletion operations to maintain balance. This ensures that the tree remains efficient and performs well over time, without requiring manual rebalancing.
- Optimized Memory Usage: B-trees optimize memory usage by ensuring that each node contains a significant amount of data. This reduces memory overhead compared to other tree structures, making B-trees suitable for environments with limited memory resources.
Properties:
- Uniform Leaf Level: All leaf nodes in a B-tree must reside at the same level. This uniformity ensures consistent access time regardless of the node's location within the tree.
- Key and Child Constraints:
- Every non-root node must hold at least ⌈m/2⌉−1 keys and at most m−1 keys, where m is the order of the B-tree.
- All non-leaf nodes, except the root, must have at least ⌈m/2⌉ children.
- If the root is not a leaf node, it must have a minimum of 2 children.
- For a non-leaf node with n−1 keys, it must have exactly n children.
- Ascending Order of Keys: Within each node, the keys must be arranged in ascending order. This organization facilitates efficient search operations within the node.
Usage:
- Disk-Based Storage: B-trees are particularly suitable for scenarios where data is stored on disk due to their ability to minimize disk I/O operations. By maximizing the number of keys in each node, B-trees reduce the number of disk accesses required to retrieve data, thereby optimizing performance.
- Database Systems: B-trees are extensively used in database systems for indexing large datasets. They enable fast search, insertion, and deletion operations, crucial for efficient database management and query processing.
- File Systems: File systems employ B-trees to organize and manage file metadata efficiently. By maintaining a balanced tree structure, file systems can quickly locate files and directories, enhancing overall system performance.
- Networking: B-trees find applications in networking protocols and systems for efficient routing table management. They facilitate quick lookup and retrieval based on keys, supporting seamless data transmission and routing decisions.
Example 1
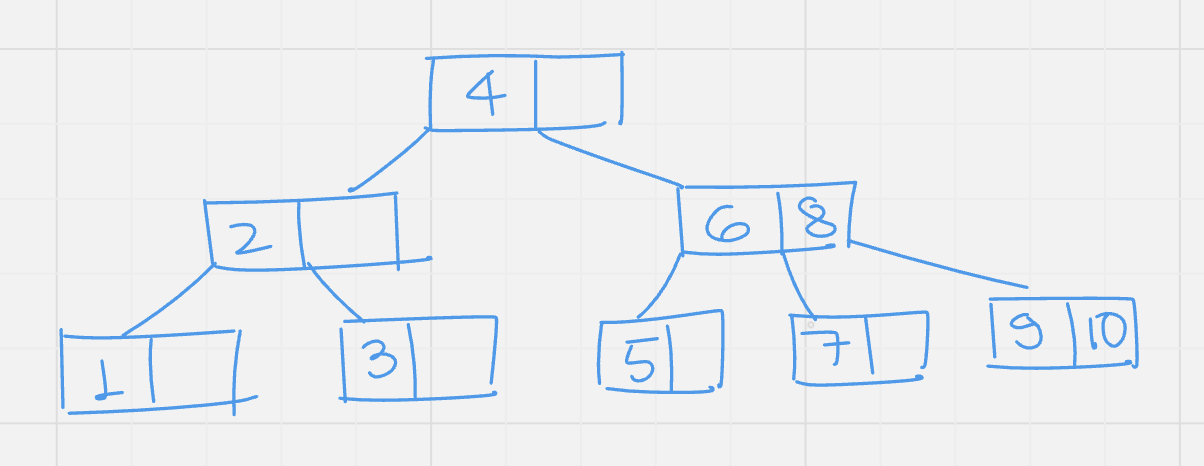
Construct a B-Tree of Order 3 by inserting numbers from 1 to 10.
Solution:
order(m) = 3
max allowed keys= m-1 = 2
Insert (1): create a new node. Insert 1 into the node. The new node will act as the root node.

Insert (2): The existing node acts as both leaf node and root node. Since there is an empty position in the leaf node, value 2 will be inserted into the node.
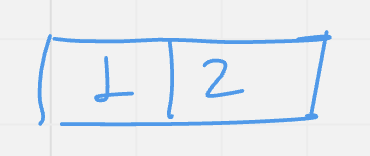
Insert (3): value 3 will be added to the given root/leaf node. Since there is no empty position, the node will be splitted and the middle element will be sent to its parent node. There is no parent node, so the middle element will be inserted into the new node, which will be a new root of the tree.
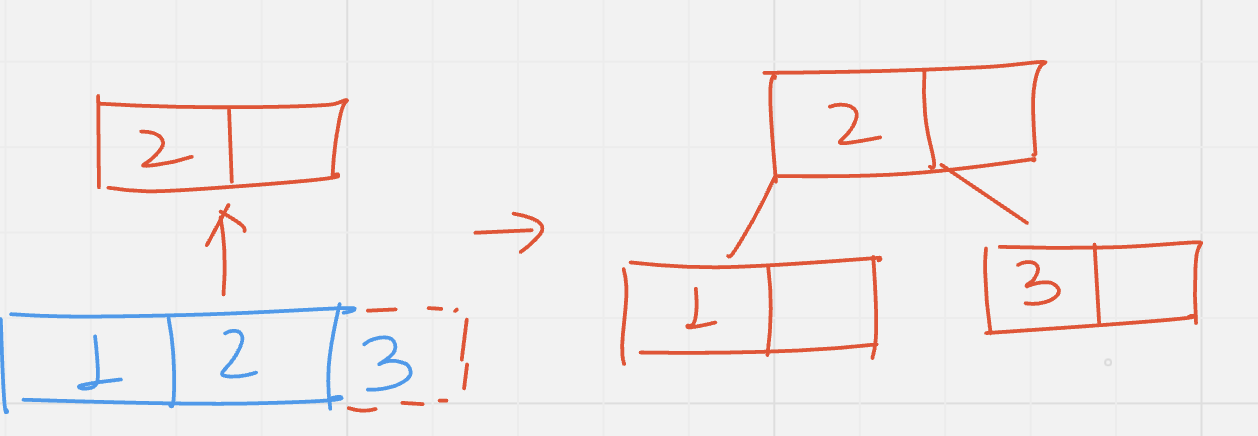
Insert (4): In B-tree, an element is always added at the leaf node. The value 4 is first compared with root node(2). Since 4 >2, we move to the right, there is empty position in the node containing 3, so 4 is added to the empty position now.
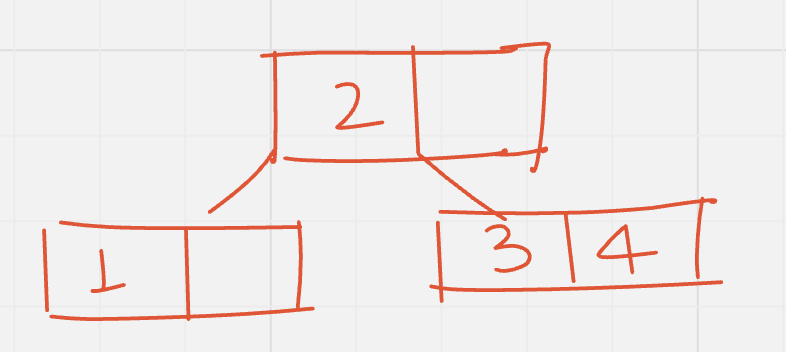
Insert (5): following above technique, to insert 5 move to the right subtree, there is no empty space there, split the node move middle element 4 to its parent:
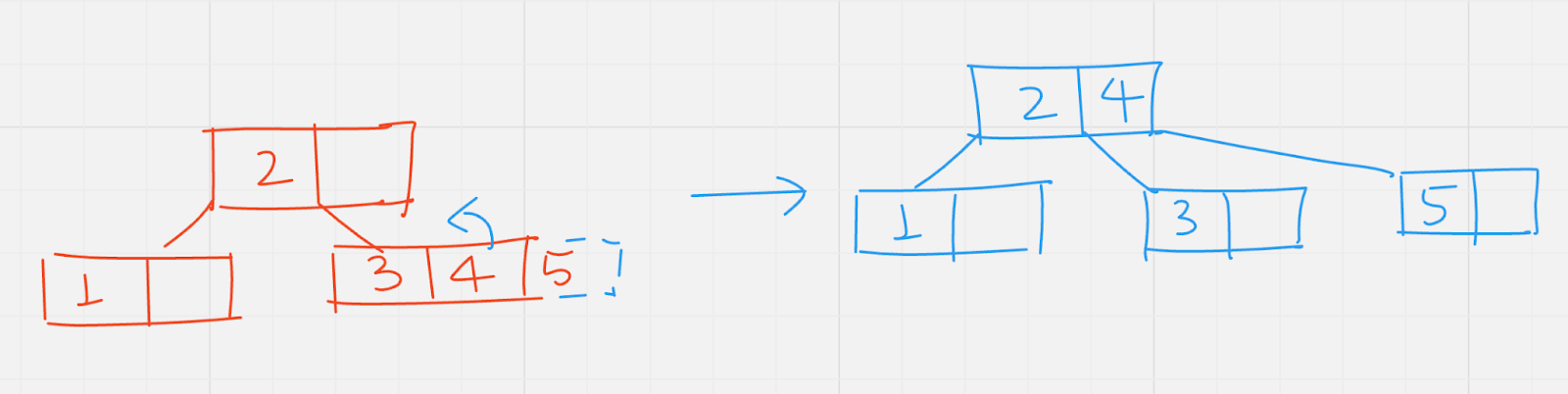
Insert (6): compare 6 with root values, move right subtree of 4, there is empty space in node containing 5, insert 6 there.
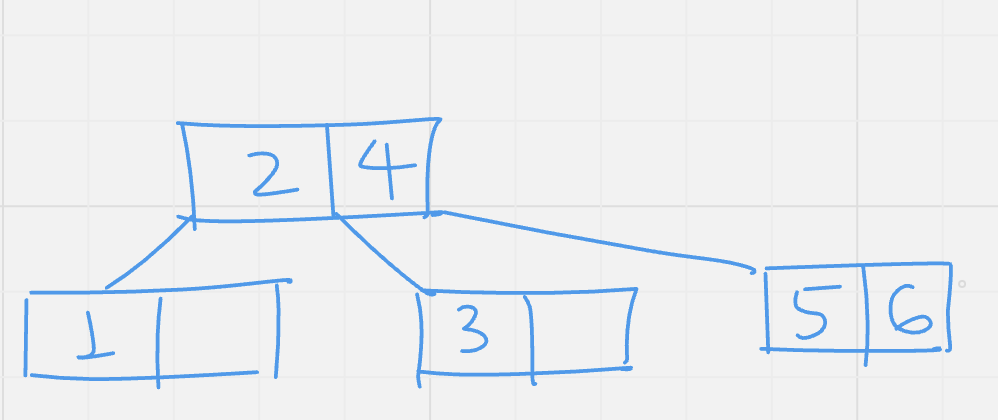
Insert (7): to insert 7, move to the right of 4, in the leaf node, no empty space is there. So split up the node move 6 to its parent which is the root, the root node too have no empty space. Now the root node is split up, 4 is moved to its parent, which does not exist, so a new root node with value 4 is created.
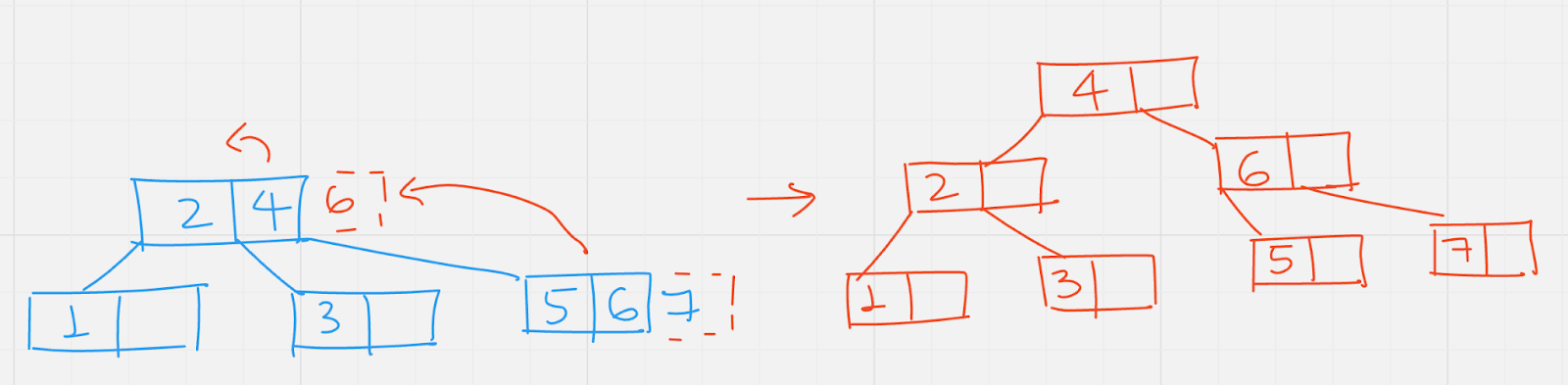
Insert (8): compare 8 with root(4), move to its right, compare 8 with 6, move to its right, there is empty space in node with 7, insert 8 there.
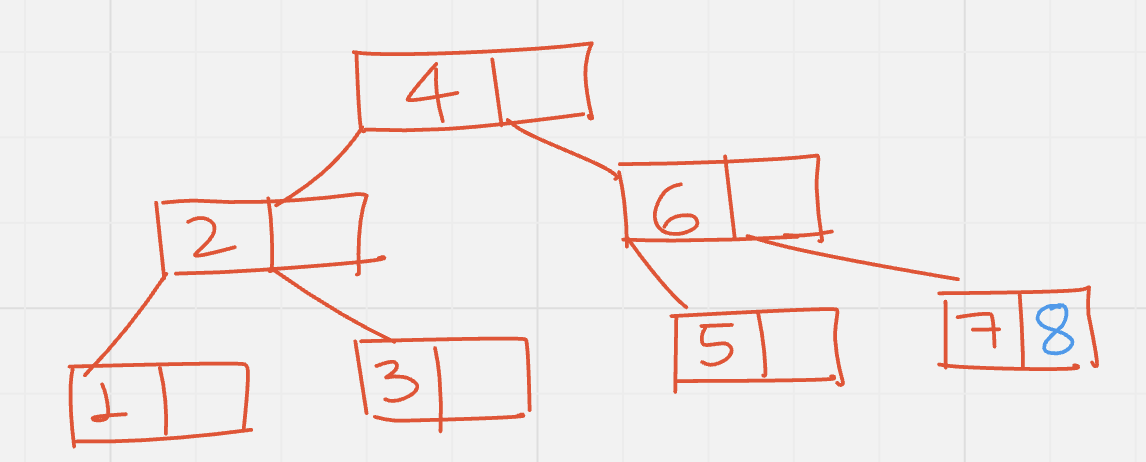
Insert (9): move to the right of 4 and 6, the leaf node has no empty space. Split up the node, send the middle value 8 to its parent.
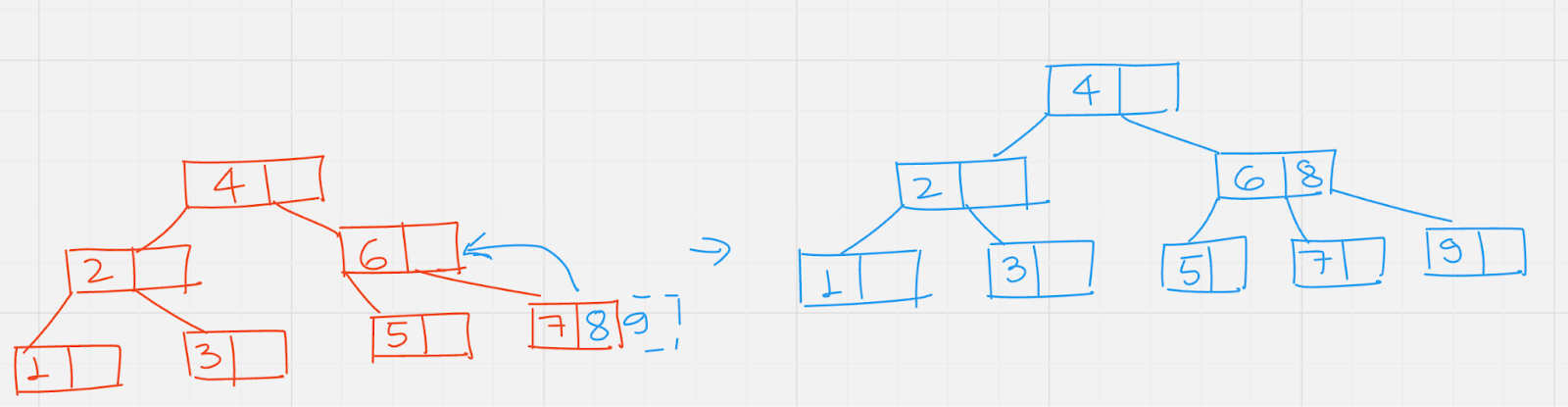
Insert (10): move to the right of 4 and 8, there is empty space in leaf node, insert the node there.
Example 2:
Construct a B-Tree of Order 4 by inserting numbers:
5, 3, 21, 9, 1, 13, 2, 7, 10, 12, 4, 8
Solution:
Order (m) = 4
Max. allowed keys = m-1 = 3
Insert: 5,3,21

Insert : 9
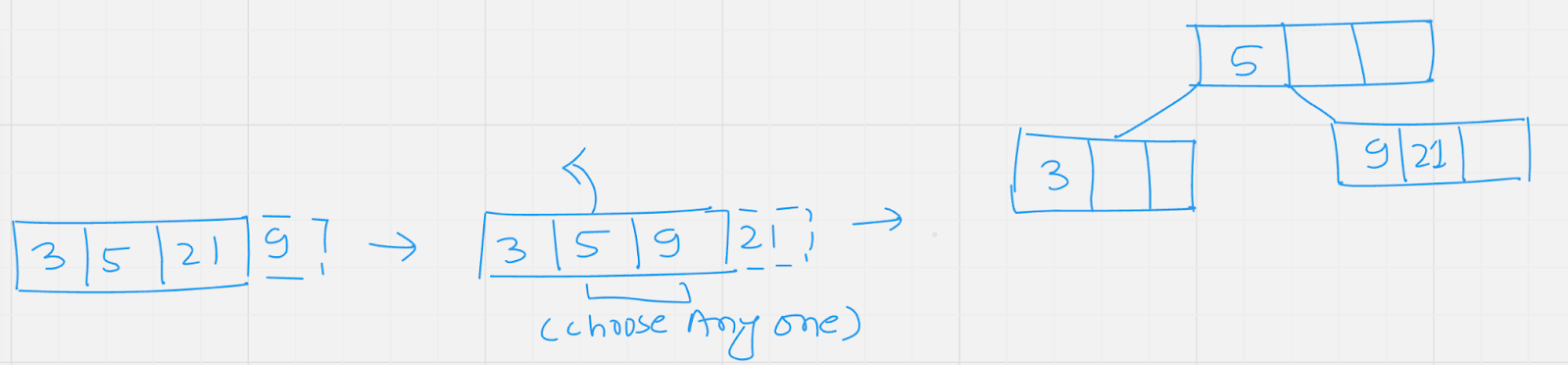
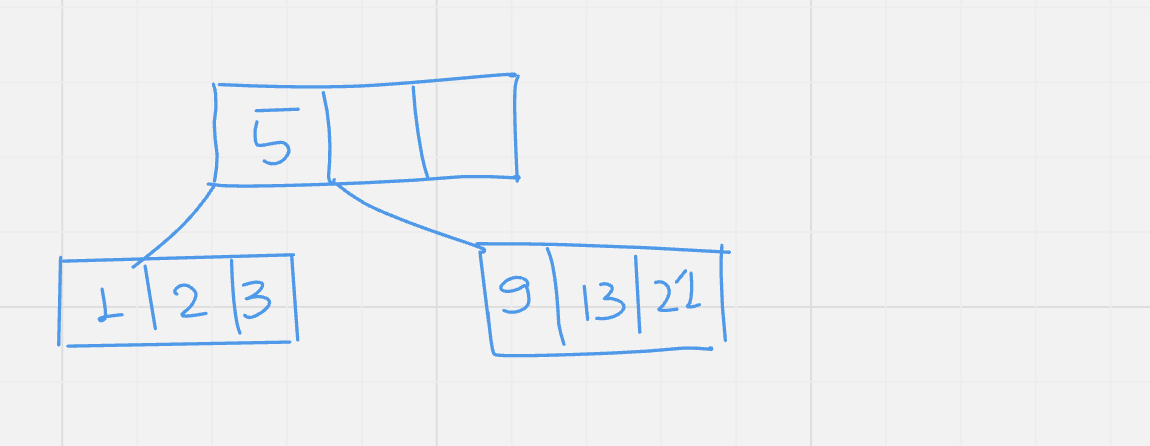
Insert : 1, 13

Insert : 2
Insert : 7
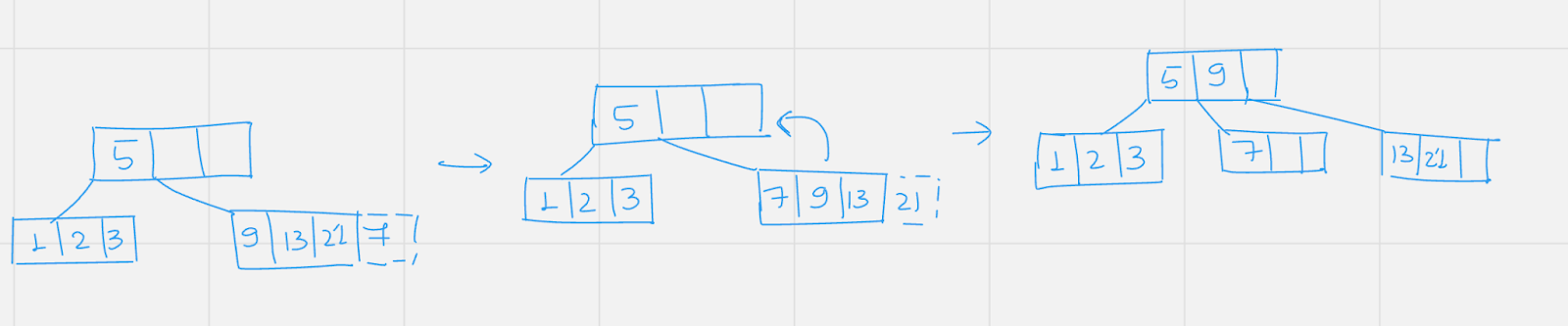
Insert: 10
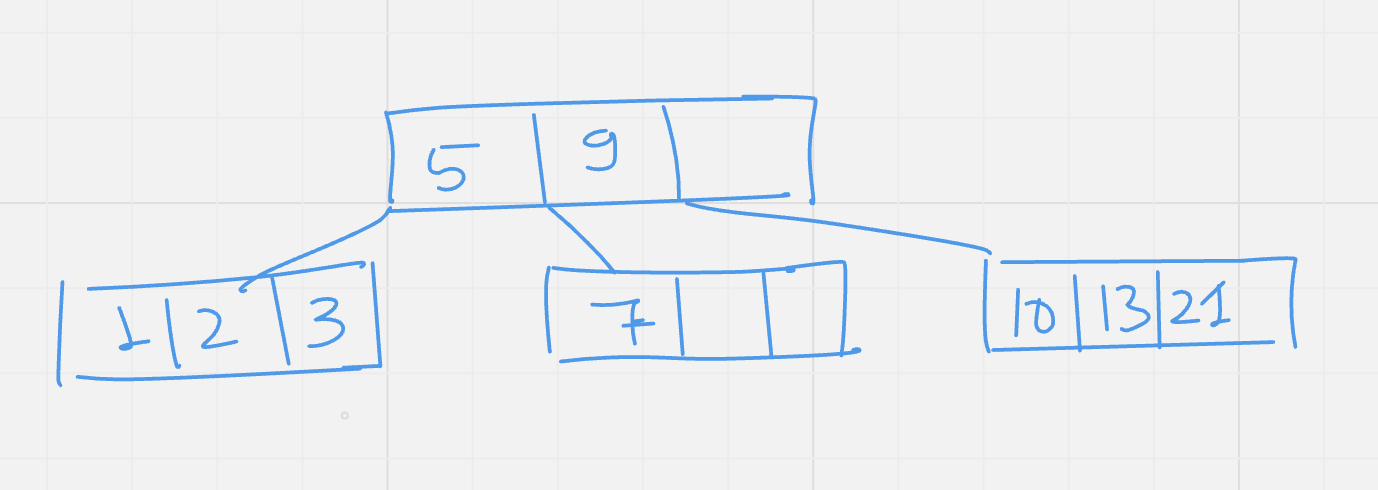
Insert : 12

Insert: 4
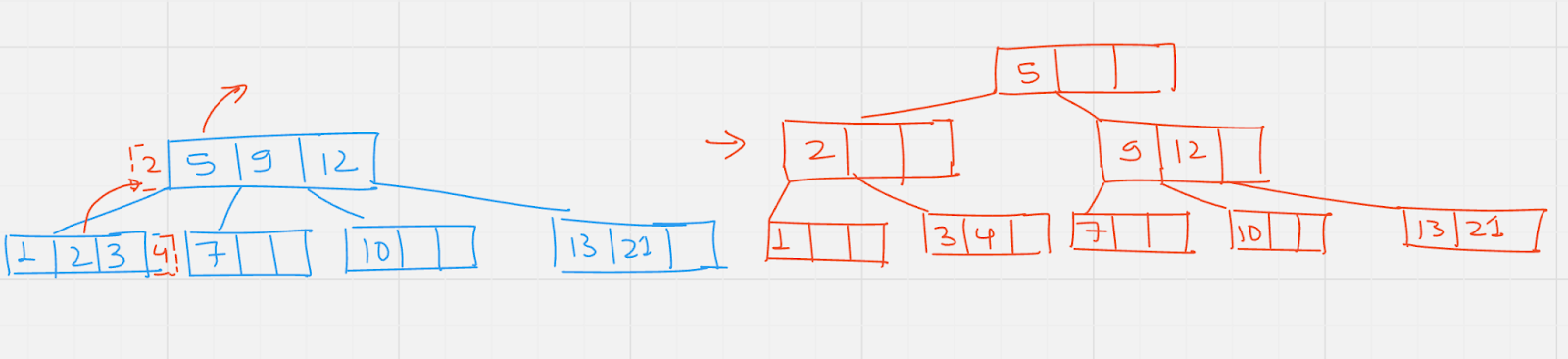
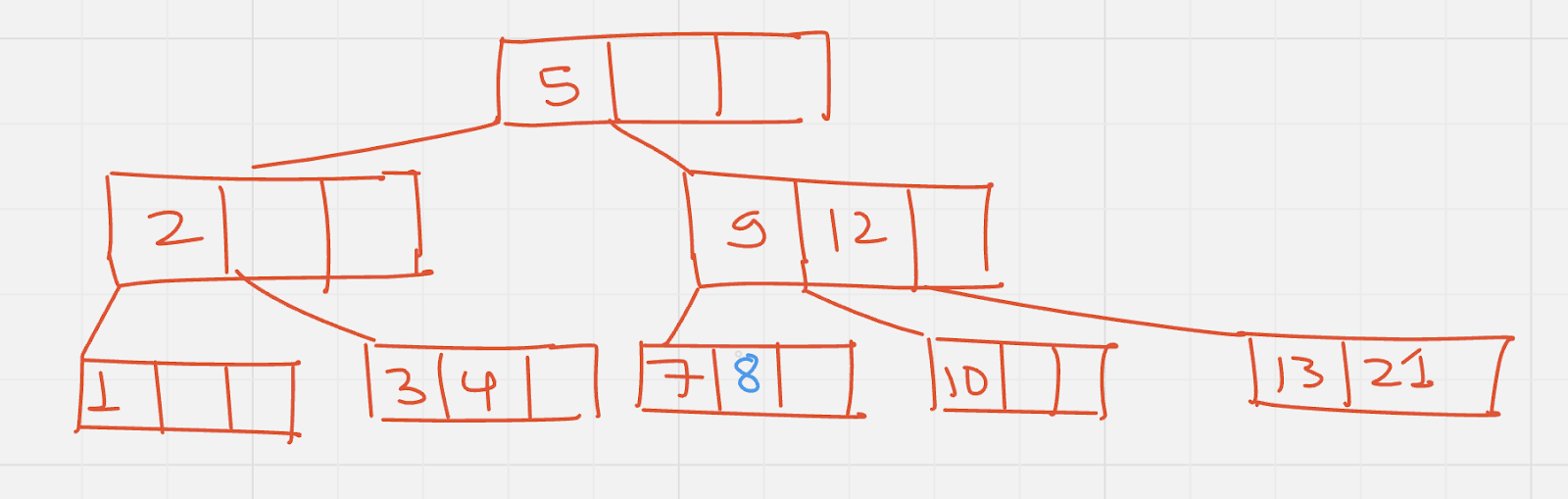
Insert : 8
Search Operation
The search operation is the simplest operation on B Tree.
The following algorithm is applied:
- Let the key (the value) to be searched by "k".
- Start searching from the root and recursively traverse down.
- If k is lesser than the root value, search left subtree, if k is greater than the root value, search the right subtree.
- If the node has the found k, simply return the node.
- If the k is not found in the node, traverse down to the child with a greater key.
- If k is not found in the tree, we return NULL.
Insertion Operation in B-Tree
In a B-Tree, a new element must be added only at the leaf node. That means, the new keyValue is always attached to the leaf node only. The insertion operation is performed as follows:
Step 1 - Check whether tree is Empty.
Step 2 - If tree is Empty, then create a new node with new key value and insert it into the tree as a root node.
Step 3 - If tree is Not Empty, then find the suitable leaf node to which the new key value is added using Binary Search Tree logic.
Step 4 - If that leaf node has empty position, add the new key value to that leaf node in ascending order of key value within the node.
Step 5 - If that leaf node is already full, split that leaf node by sending middle value to its parent node. Repeat the same until the sending value is fixed into a node.
Step 6 - If the splitting is performed at root node then the middle value becomes new root node for the tree and the height of the tree is increased by one.
Delete Operation
The delete operation has more rules than insert and search operations.
The following algorithm applies:
- Run the search operation and find the target key in the nodes
- Three conditions applied based on the location of the target key, as explained in the following sections
If the target key is in the leaf node
- Target is in the leaf node, more than min keys.
- Deleting this will not violate the property of B Tree
- Target is in leaf node, it has min key nodes
- Deleting this will violate the property of B Tree
- Target node can borrow key from immediate left node, or immediate right node (sibling)
- The sibling will say yes if it has more than minimum number of keys
- The key will be borrowed from the parent node, the max value will be transferred to a parent, the max value of the parent node will be transferred to the target node, and remove the target value
- Target is in the leaf node, but no siblings have more than min number of keys
- Search for key
- Merge with siblings and the minimum of parent nodes
- Total keys will be now more than min
- The target key will be replaced with the minimum of a parent node
If the target key is in an internal node
- Either choose, in- order predecessor or in-order successor
- In case the of in-order predecessor, the maximum key from its left subtree will be selected
- In case of in-order successor, the minimum key from its right subtree will be selected
- If the target key's in-order predecessor has more than the min keys, only then it can replace the target key with the max of the in-order predecessor
- If the target key's in-order predecessor does not have more than min keys, look for in-order successor's minimum key.
- If the target key's in-order predecessor and successor both have less than min keys, then merge the predecessor and successor.
If the target key is in a root node
- Replace with the maximum element of the in-order predecessor subtree
- If, after deletion, the target has less than min keys, then the target node will borrow max value from its sibling via sibling's parent.
- The max value of the parent will be taken by a target, but with the nodes of the max value of the sibling.