Indexing in DBMS
INDEXING AND TYPES OF INDEXING
Indexing in a Database Management System (DBMS) is a data structure technique used to efficiently retrieve records from the database files based on some attributes on which the indexing has been done.
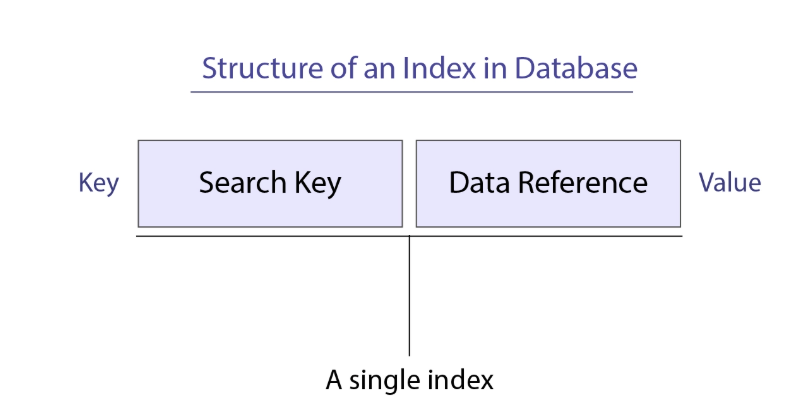
Search Key contains the copy of the Primary Key or the Candidate Key of the database table.
The second column i.e., the pointer contains a pointer or the address of the block where that particular Search key value can be found.
TYPES OF INDEXING
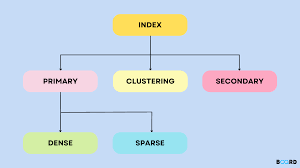
- Primary Indexing
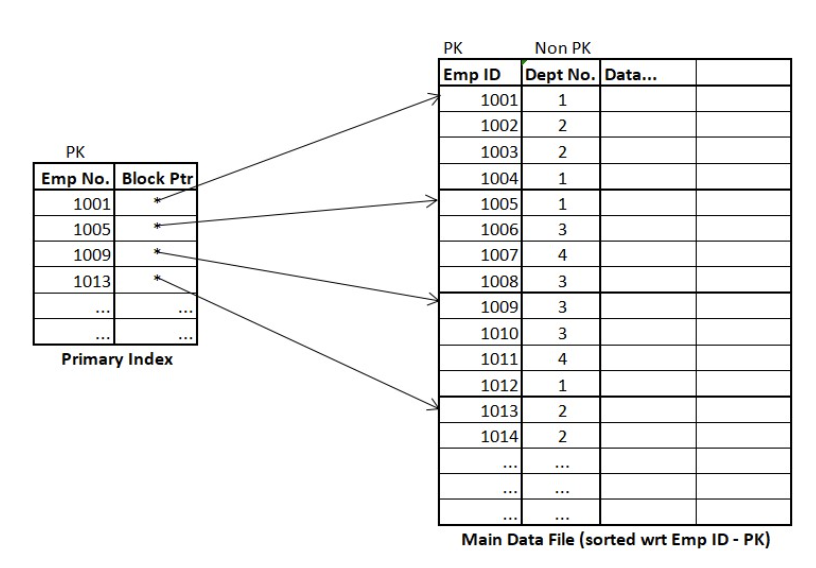
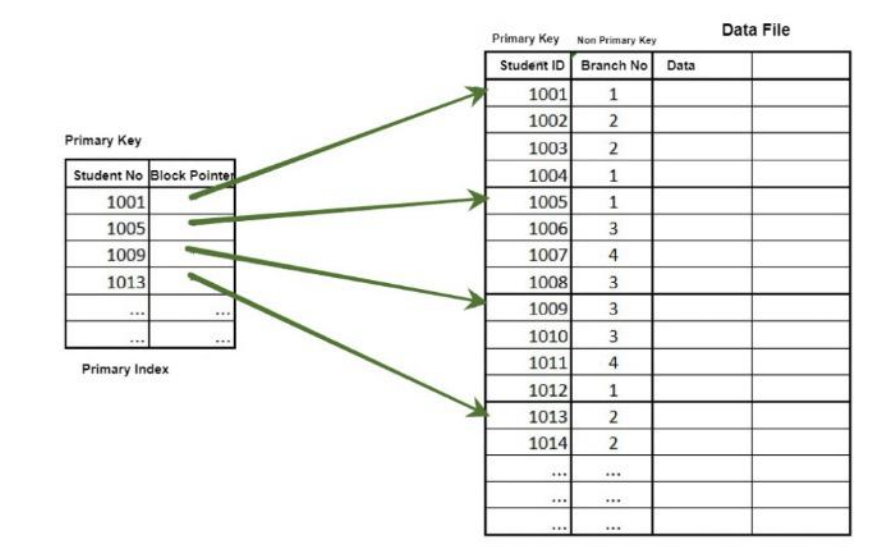
The indexing or the index table created using Primary keys is known as Primary Indexing. It is defined on ordered data. As the index is comprised of primary keys, they are unique, not null, and possess one to one relationship with the data blocks.
Data Elements must be Ordered and are Key values .
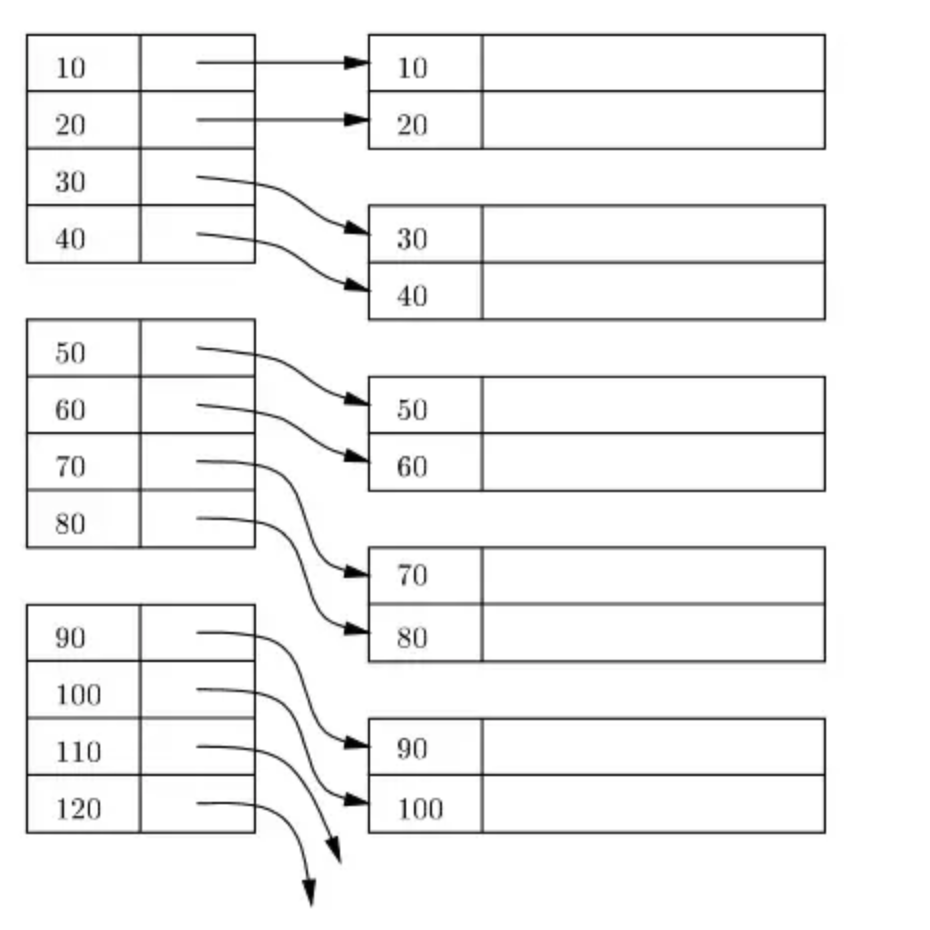
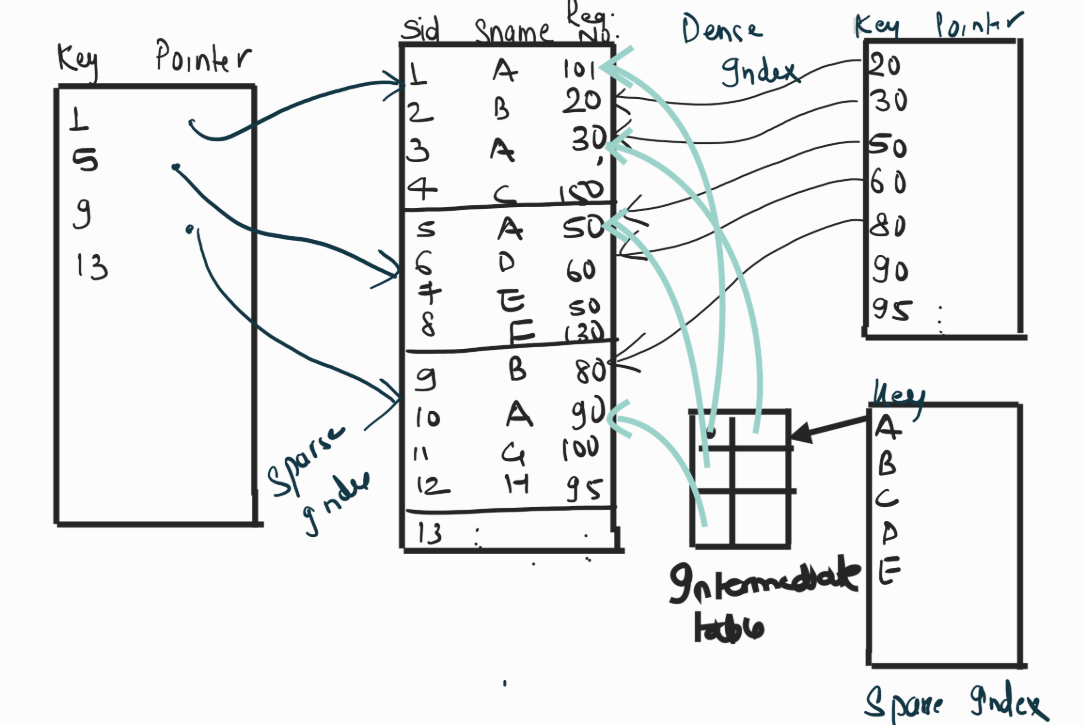
The primary index can be classified into two types: Dense index and Sparse index.
Dense Index
A dense index is an indexing method where there is an index entry for every search key value in the data file. This means that every record in the table has a corresponding index entry.
No of Index Entry = No of DB Record
Characteristics of Dense Index
- Contains an index entry for every search key value in the data file.
- Provides direct access to the data record for every key.
- Requires more storage space because it maintains an index entry for each record.
- Generally provides faster search operations since every record has a corresponding index entry.
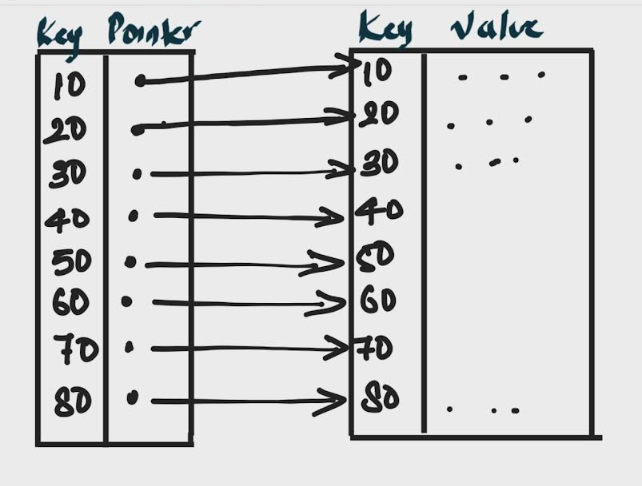
Example
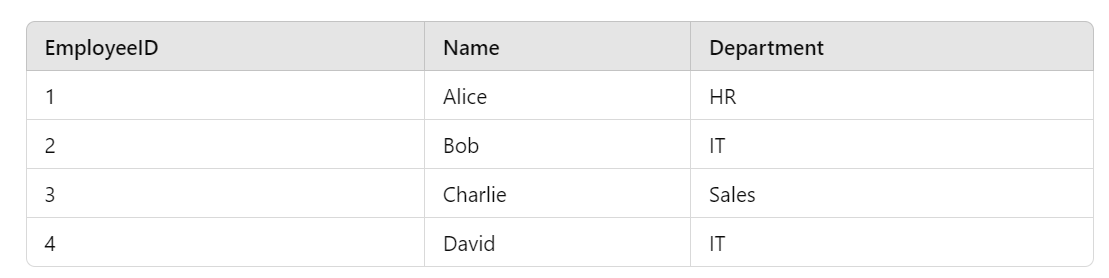
Consider a table Employee:
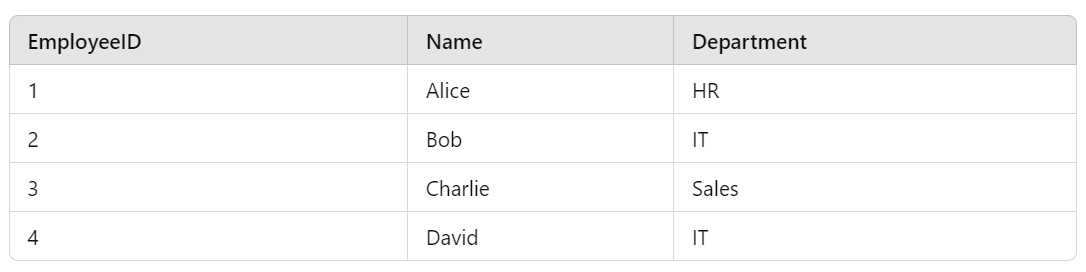
A dense index for the EmployeeID column would look like this:
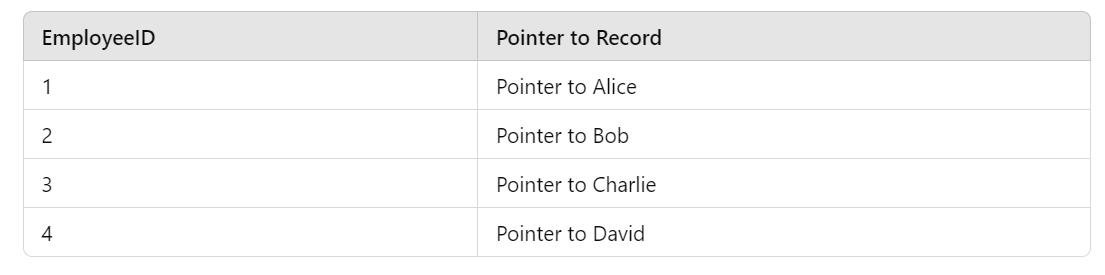
Advantages of Dense Index
- Fast Searches: Quick access to records because there is an index entry for each record.
- Direct Access: Directly points to the data record, making retrieval operations efficient.
Disadvantages of Dense Index
- Storage Overhead: Requires more storage space for maintaining the index entries.
- Maintenance Overhead: More maintenance is required for updates, inserts, and deletes, as the index needs to be updated accordingly.
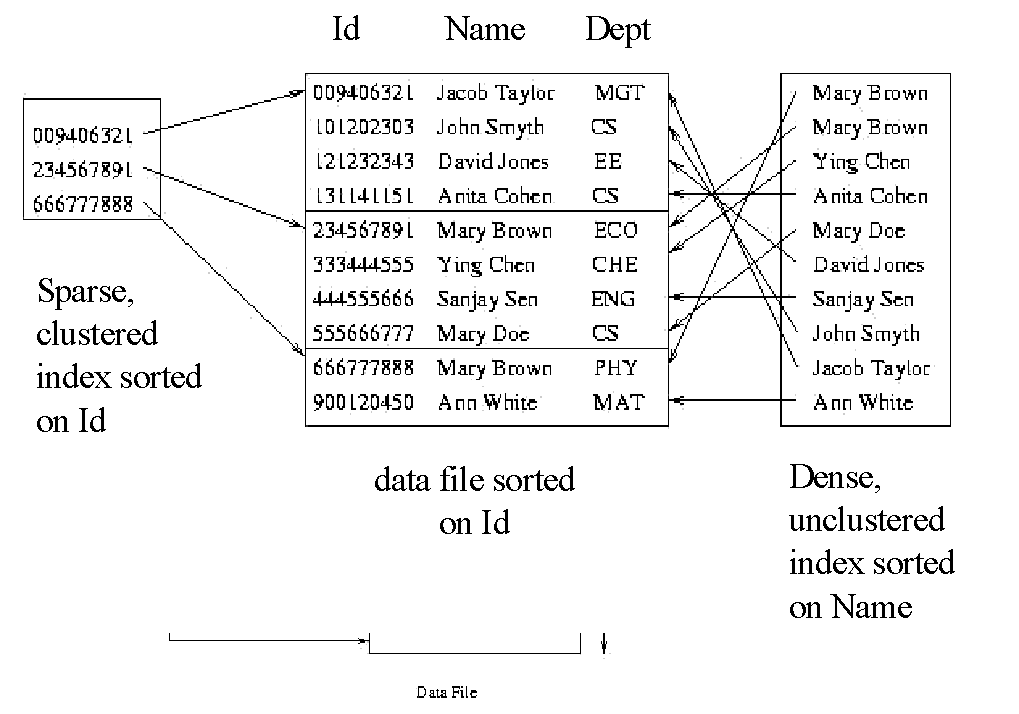
Sparse Index
A sparse index is an indexing method where index entries are not created for every search key value. Instead, index entries are created only for some of the search key values. Each index entry points to a block or a page of records.
No of Index Entry = No of Block
Characteristics of Sparse Index
- Not Every Key: Contains index entries for only some of the search key values.
- Block Level: Each index entry points to a block or page of records rather than individual records.
- Storage: Requires less storage space compared to a dense index because it has fewer index entries.
Example
Using the same Employee table:
A sparse index for the EmployeeID column might look like this:

Here, Block 1 might contain records for EmployeeID 1 and 2, and Block 2 might contain records for EmployeeID 3 and 4.
Advantages of Sparse Index
- Storage Efficiency: Requires less storage space because it has fewer index entries.
- Maintenance Efficiency: Easier to maintain compared to dense indexing, especially for large datasets.
Disadvantages of Sparse Index
- Slower Access: May require additional block reads to locate the exact record, making searches slightly slower compared to dense indexing.
- Indirect Access: Provides indirect access to records, which may increase search time.
When to Use
- Dense Index: Suitable for smaller tables or tables where search speed is critical, and storage overhead is not a primary concern.
- Sparse Index: Ideal for large tables where storage space is a consideration and search operations can tolerate a slight performance overhead.
2. Clustering Indexing
A clustered index determines the physical order of data in a table. In other words, the order in which the rows are stored on disk is the same as the order of the index key values. This helps reduce the cost of searching because related data is kept close to each other.
In clustered indexing, the data is stored in an ordered file, usually based on a non-key field. This ordering can be based on a primary key or, in some cases, a non-primary key. When an index is created on non-primary key columns, which may not be unique, the solution is to combine two or more columns together to form a unique value.
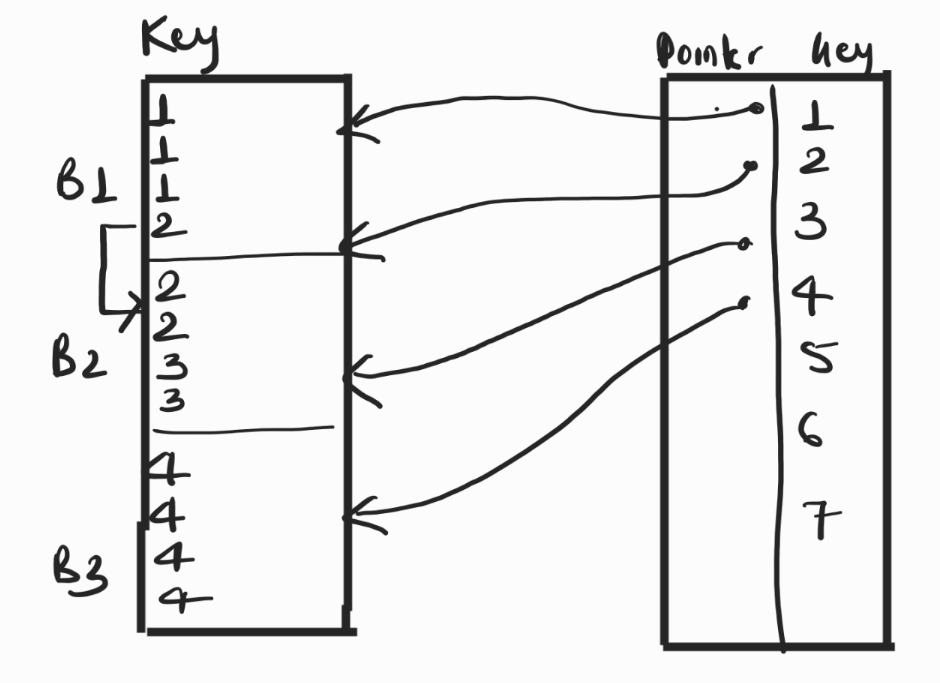
Clustered indexing works by grouping records with similar properties together. For example, students can be grouped by their semester, such as first-semester, second-semester, and so on.
Clustered indexing utilizes only sparse indexing. The data in the search table is ordered and unique. The arrow from B1 to B2 is called block hanker .
Book Table
| BookID | Title | Genre |
|--------|----------------------|-----------|
| 3 | A Tale of Two Cities | Fiction |
| 1 | Database Systems | Academic |
| 4 | Python Programming | Technical |
| 2 | The Great Gatsby | Fiction |
If we create cluster index , the table will look like
| BookID | Title | Genre |
|--------|----------------------|-----------|
| 1 | Database Systems | Academic |
| 2 | The Great Gatsby | Fiction |
| 3 | A Tale of Two Cities | Fiction |
| 4 | Python Programming | Technical |
3. Secondary Indexing
In databases, searches can be performed on both primary key and non-primary key values. Secondary indexing is used when the data is unordered, and the values can be either key elements or non-key elements. This approach involves using two indexes to facilitate quicker and easier searches.
For key values, a primary index is used, which is a sparse index. For non-key values, a secondary index is created. In this case, the non-key values are first ordered in a secondary table. Then, a separate index table with a dense index is prepared to manage these non-key values.